Introducing the Microcontent Client
Microcontent is information published in short form, with its length dictated by the constraint of a single main topic and by the physical and technical limitations of the software and devices that we use to view digital content today. We’ve discovered in the last few years that navigating the web in meme-sized chunks is the natural idiom of the Internet. So it’s time to create a tool that’s designed for the job of viewing, managing, and publishing microcontent. This tool is the microcontent client.
For the purposes of this application, we’re not talking about microcontent in the strict Jakob Nielsen definition that’s now a few years old, which focused on making documents easy to skim. Today, microcontent is being used as a more general term indicating content that conveys one primary idea or concept, is accessible through a single definitive URL or permalink, and is appropriately written and formatted for presentation in email clients, web browsers, or on handheld devices as needed. A day’s weather forcast, the arrival and departure times for an airplane flight, an abstract from a long publication, or a single instant message can all be examples of microcontent. But, as we’ll see, these pieces of microcontent are best handled by a program designed for the task.
The microcontent client is an extensible desktop application based around standard Internet protocols that leverages existing web technologies to find, navigate, collect, and author chunks of content for consumption by either the microcontent browser or a standard web browser. The primary advantage of the microcontent client over existing Internet technologies is that it will enable the sharing of meme-sized chunks of information using a consistent set of navigation, user interface, storage, and networking technologies. In short, a better user interface for task-based activities, and a more powerful system for reading, searching, annotating, reviewing, and other information-based activities on the Internet.
We’ve been talking about a microcontent client for years now, and finally all the pieces and infrastructure are in place to build it. The best parts of the microcontent client are that it’s fully backwards compatible, it can leverage the unused abilities of existing content to improve their utility, and that its appearance in the software market is inevitable.
The best part of the microcontent client is that its appearance in the software market is inevitable.
While the primary raw material for the tool is, of course, our existing universe of HTTP-delivered HTML documents, a strength of the microcontent browser is that it can also navigate the nascent web of XML-tagged documents, including RSS and XHTML, and such documents confer advantages on both the publisher and reader when created according to the standards we’ve all been preaching about for so long. This tool could also eventually integrate individual messages in other formats as peers to information in HTML documents, making email messages, NNTP usenet messages, and instant messenger messages available through the same viewing application. More immediately, the microcontent browser would be a superior interface for reading and commenting on the content on existing sites where microcontent is a primary focus, such as weblogs and news sites. The microcontent browser’s extensibility would allow it to the best end-user interface for the consumption of web services.
In its ideal implementation, the microcontent browser is a combination of a desktop software application and well-designed web services, interacting together to parse our existing HTML, XHTML, and XML documents into tomorrow’s semantic web.
The Application
During the past few years that I’ve been discussing the microcontent client with friends, I had taken to referring to it by different names, such as The Thing, or the SuperBrowser, or John Rhodes’ term, the Google Client. Finally I settled on the name microcontent client because I didn’t want to get tied to the word "browser" So many of the shortcomings of our current Internet experience are encapsulated in the fact that our primary access application is a "browser", when our need to browse is dwarfed by our needs to search, to aggregate, to store, and most importantly to create. The browser’s a lousy authoring tool, which makes sense since it was never designed to perform the task. Lest I seem caught up in my own hype, I”m not suggesting that the standard Internet browser will go away. Most of us still have NNTP Usenet newsreaders on our systems, and many of us have Telnet or FTP clients, so clearly there is room for keeping the right tool for the job.
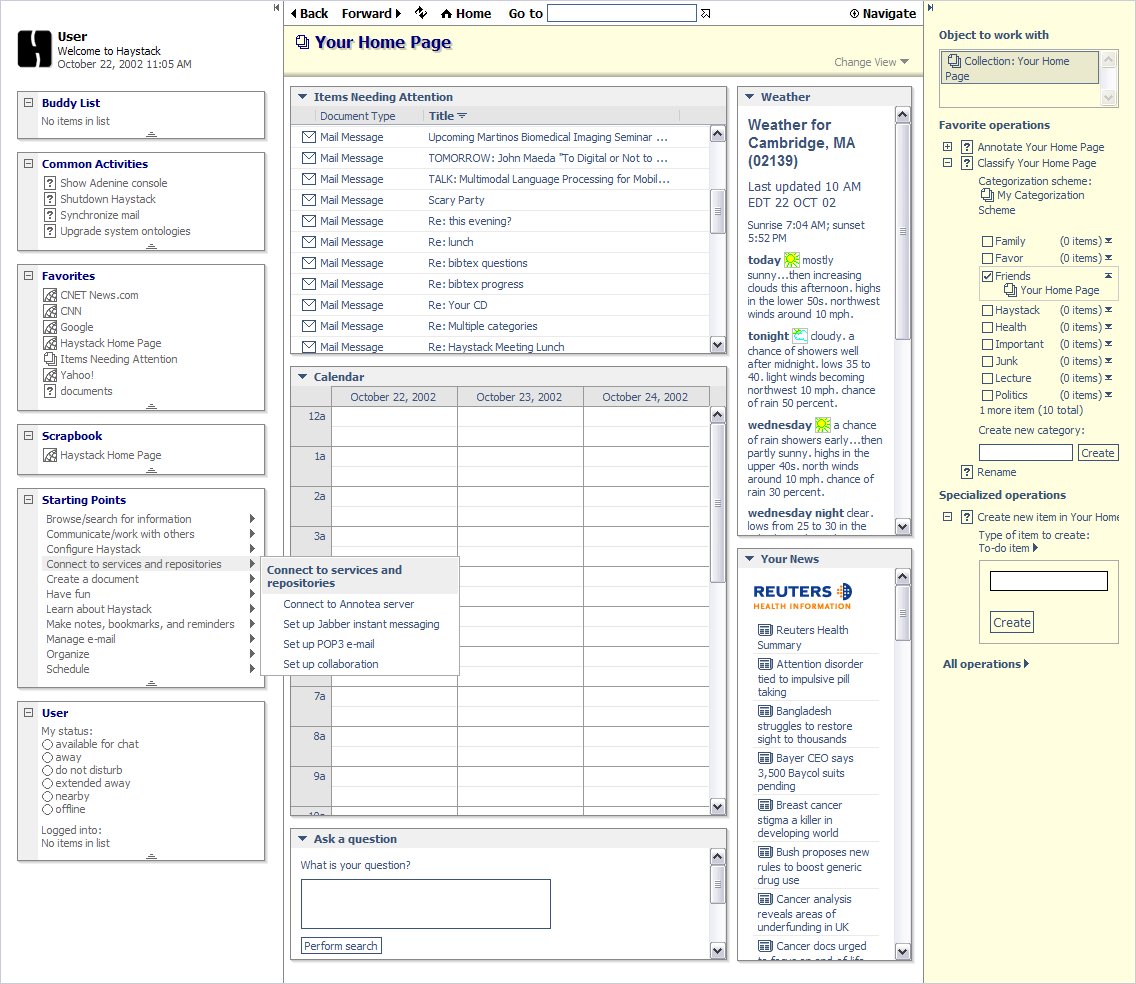
But throwing away the browser to focus on a new application that subsumes most of its functionality, raises a lot of questions. Shouldn’t contact information for a person we’re communicating with look be displayed and manipulated the same way, regardless of whether if it was searched for with Google or retrieved from our existing contacts list? Doesn’t a three-pane view work pretty well for more than just files and email messages? What does the user experience of a meme-focused program look like? Well, we’re fortunate to have a few examples around already.
None of the existing microcontent applications adequately address authoring. Each of them, however, does an excellent job with one facet of the consumption needs of a user. We’ll be stealing ideas from each of these clients along the way.
Searching

Searching is a key task. It’s the most important thing we do. And, until a few years ago, nobody had made a tool for searching the Internet. Now we’ve got a few, and they’re all great. The first, and most popular, is Google’s Toolbar. The toolbar succeeds on several levels. It has near-instantaneous load time, it has a minimal but highly configurable interface, and it of course returns excellent results. The few downsides are that it is platform-specific, (though an open clone exists) it requires a standard Internet browser, it uses the same view for browsing search results and viewing them, and it is not extensible by an average developer. Despite these shortcomings, this free tool is the most powerful search client available and has inspired similar useful utilities such as Dave’s Deskbar and Nutshell.

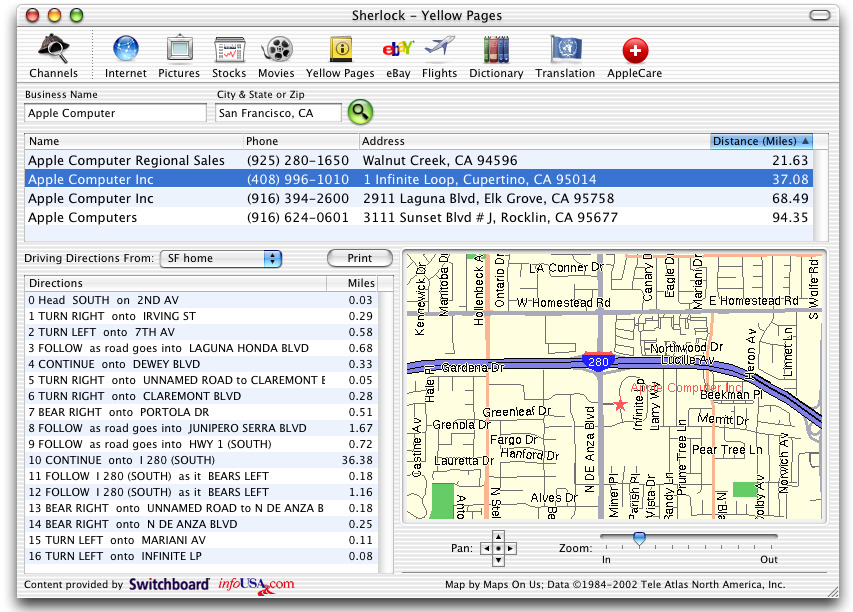
The only other credible Internet searching application is Watson, and Apple’s take on the same idea, Sherlock 3. These two client programs are the closest examples we have to the eventual user experience of the microcontent browser. Besides being Aqua-pretty, these two are the first mainstream applications to recognize that people don’t want the entirety of the web pages they’re viewing today, they want the tiny portion of the screen that pertains to their task at hand. The search results are presented in a consistent manner, and future versions of these tools will no doubt let users filter, sort, and manipulate those results consistently, regardless of what type of search they’re performing.
The most critical technical feature for these tools are their extensibility. Users can install, and even createnew types of custom searches, feeding information into the tool for display in whatever presentation is appropriate. Others have commented on why Watson was superior for being a platform, rather than merely an application, but Apple’s recent release of documentation for Sherlock channels strengthens their advantage in this area, especially as their model uses simple scripting languages for extensibility instead of full programming languages. But the veryneed for plugins to perform different types of searches reveals that these tools are focusing on the HTML-obscured Web that exists today, as opposed to the XML-revealed Internet that is being born.
The content that will be searched for by the microcontent client will largely be described with semantic XML tags, allowing the user interface of the searching functions to conform to the appropriate presentation of the data, and negating the need for complicated, fragile plug-ins that perform what is essentially well-hidden screen scraping. XHTML pages or XML documents will reveal themselves to the microcontent client with every node or leaf appearing as a result in the display pane of the application.
Part of the value of being extensible is that this tool would understand contexts for XML data, and would give the user appropriate searching or authoring tools for different types of information. Spreadsheet and tree controls are obvious first choices, but even author-suggested arrangements of form controls for the editing of a particular data type would be easy to arrange. Watson and Sherlock already do this by having the viewing pane conform to the input and output needs of the web service being accessed, and it seems that tools like Microsoft’s upcoming XDocs may have an understanding of DTDs that would allow the client to present the appropriate UI for each data task. A central repository for each DTD, analogous to UDDI, could give the appliation context for rendering a specific document type.
Aggregating
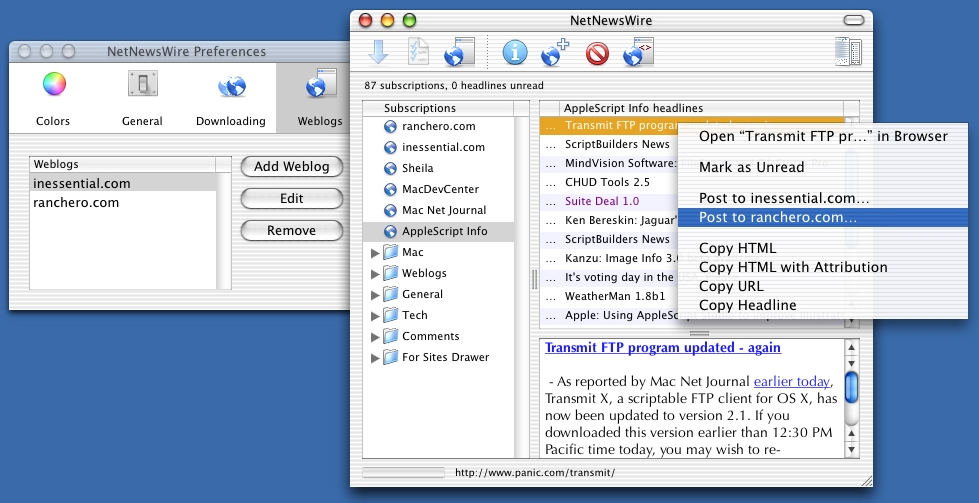
Aggregating has been receiving a lot of attention in the world of microcontent authors of late, which is disappointing but unsurprising because it’s one of the easiest, least important parts of the microcontent realm. The standards-bearers for content-aggregation clients are NetNewsWire on the Macintosh and Newzcrawler and FeedReader on the PC.
Most of the current talk that is leading towards the microcontent client is unfortunately focused around the part that is both hardest to describe and of least utility to average users. This, of course, is not entirely unexpected, given the technical bent of the people involved in these discussions so far. For similar reasons, there are the greatest number of examples of software that have the right features in this regard, but they tend to have designs that either can’t accommodate the other necessary features of the microcontent client, or that would stymie any user interested in using such additional functions.
The creation of content for use by aggregation systems has been slow so far, despite all of the noise being generated about it, mostly due to the fact that it requires effort on the author’s part right now. The current generation of tools doesn’t make syndication formats automatic, and aggregation consumers pay for the indecision and quarreling in this realm. This situation will solve itself in the next year as authoring tools incorporate syndication seamlessly, and, more importantly, as the process of generating syndication feeds becomes invisible.
The microcontent client aggregates data both actively and passively.
The microcontent client aggregates data both actively and passively. Active aggregation is the selection, storage, and updating of syndication feeds that are explicitly linked in a browsed page, similar to the orange XML buttons on many sites today. But the future of syndication is the auto-discovery of feeds referenced in link tags in the document header. NetNewsWire and Newzcrawler are accomplishing this already, and most online and desktop tools will evolve to use this functionality shortly. More importantly, all of the content created with the client’s authoring tools and all of the metadata generated during the use of client will be accessible as syndication feeds as well.
{kind=link}
One current need for syndication tools is the manipulation and storage of favorites or bookmark lists. Recalling that web pages are stories or tools, it will be useful to decide which of a user’s favorites are stories, as those ought to be handled as a syndication feed as well. Frequently-updated story pages like news sites and weblogs are a natural part of any automatic update feature, whereas tool sites should be omitted from update-management systems.
It’s important to remember that most users today don’t have favorite sites. They use web applications, but aren’t aware that there is a universe of narrative, document-centric sites on the Internet, other than news sites. The improved user experience of the microcontent client should act as a catalyst for average, non-technical users to begin participating in the majority of the Internet that is not focused around web applications, such as personal websites and aggregation-friendly news sites.
Authoring
Creating content with the microcontent client takes place both actively and passively. Active authoring is template-independent and can easily output to XML or XHTML as appropriate. Passive authoring is accomplished through the assignation of qualitative judgements, as well as through the mere viewing of content, letting the context of a path of navigation or a document’s place in time be a method of attaching metadata to an item. In the microcontent client, history is a document.
The mere clicking of a thumbs-up or thumbs-down button (or, to use the parlance of a popular filesharing website, describing the content by clicking a link that says [This is Good] or [This is Bad]) would let a user signify the merit of a piece of content, either for their own recall, or in the future by those who are registered in their network of trusted peers.
Also valued in this model is the value of quantitative surfing data. The order in which items were browsed often reveals a lot about the thought processes involved. Browsing history should always have been threaded, to reflect the surfing habits of power users prone to spawning new windows or tabs in order to follow tangents. With the benefit of a new architecture, this tool could accommodate such technologies. In addition, keywords could be assigned according to the day of the week or time of the day an item was browsed, and by which items were viewed simultaneously.
Fortunately, for all of this data, simple XHTML and XML are more than enough to encode and store the required information. For the authoring of individual pieces of content, a simple web-service hookup to a server enabled with WebDAV or MetaweblogAPI provides a repository for the storage of newly-created content.
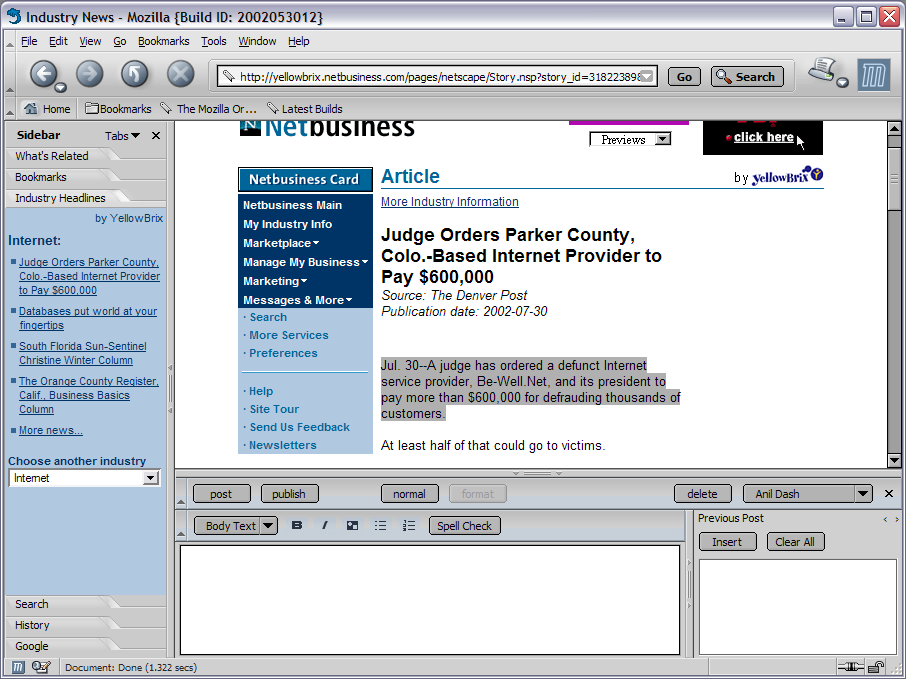
At a simpler level, a three-pane layout for the client would present the bottom right pane as an authoring tool that would use the displayed content for context. A crude version of this can be assembled today with the MozBlog extension for the Mozilla browser, as depicted in the Mozilla Weblog Client illustration, or in similar tools like bloggenmoz.
We’re not merely boldly forging a Usenet For The New Millenium
It’s worth noting the remarkable resemblance that these simpler tools have to a traditional Usenet newsreader. Many of the more immediate benefits of the semantic web exposed by the microcontent client will appear to be extending the positive aspects (yes, there weresome) of Usenet to the web, including threading, filtering, and immediate response to contents, along with tracking of new content and marking information as having been read or unread. But we’re not merely boldly forging a Usenet For The New Millenium; The XML content created by our new client will leverage existing standards like XLink to effectively make every piece of content be crossposted to every relevant group, without any duplication of content or wasted space. In seeing the Semantic Web as the New Usenet, we have to consider that every topic, every organization, everyauthor is a newsgroup, too.
More subtly, the passive authoring of the microcontent client creates content that even the "author" doesn’t yet know they want to read. We’ve been talking for years about the wasted power of our desktop machines, now that games are the only applications that truly make demands of our systems. But users running the client will find unused processor cycles being tapped to discover relationships and intersections between ideas. While you type, instead of autocomplete fixing your sentences, an agent creates ad-hoc categories and uses a Google service to add relevant links for your perusal or review when the topic is revisited. The results would be as appropriate and on-topic as today’s grammar-checkers, probably. Which is to say, frustrating, but still useful at times, and constantly improving. Being able to track all of this information all the time, though, should be one of the most liberating implications of the virtually unlimited storage that we’ve got in our machines.
The ramifications of having massive amounts of independently-authored content that’s available by default to aggregators will be exciting to watch, as user demand for content that’s free from the frustrations of today’s news/information sites, like pop-ups, ad banners, privacy intrustions increases.
Not that there won’t be new privacy impliations, of course, but it should at least be refreshing to visit new ones.
More important is that new content will be suggested not just by the sources you’re already viewing, but by people who are reading content that’s similar to your taste. One of the greatest simple pleasures of stealing music during Napster’s heyday was browsing other users’ lists of shared files. The experience that got so many users hooked is best described as collaborative (or distributed) serendipity. Randomness that we control has limits in our own perceptions and experiences. All of us knew how to search for songs we wanted; None of us knew how to find songs we didn’t know we wanted. This spontaneity requires a networked community, and will be the best defense the semantic web has against the threat of homogeneity and monoculture. The problem has never been that there weren’t thousands of people publishing content; The problem has been that the tools make them infinitely harder to find than the companies with the biggest promotional budgets.
Building the Client
It’s a huge task, making this tool. People want to be using it, and it’ll be important that the first versions come pretty close to getting it right, so it doesn’t poison the well for those who make later attempts. So what will it take to build it? Well, you remember during all of the vaporware years, everyone working on Mozilla kept claiming it’s a toolkit for building Internet applications, not just a browser? Yet, the first thing that was built was a browser suite. And then, once that came to version 1.0, they set about on a new project, and its goal was to build… a web browser. While those are admittedly great efforts that I use every day, I think it’s time to push them past their limits a bit. Phoenix’s relative speediness even has me a bit forgiving of XUL, especially as an application framework separate from Mozilla, though it still may not be the way to go. The basics, however, are exemplary. Libraries for networking, HTML rendering and handling different internet protocols will shave off months of development and debug time for a team trying to make the microcontent client.
The greatest task that remains is integration. Nearly every piece exists today.
There’s a lot to be learned by the pieces that exist today. The efforts put into tools like Chimera, RapidBrowser and K-Meleon indicate that users want the aesthetic and functional advantages of a platform-native application. We’ve seen that Sherlock, NetNewsWire and Watson are adopted for the attractiveness of their interfaces as much as their functionality. But running each of these appliations independently, along with a standard web browser and perhaps a blogging desktop client, won’t leave room for anything else on a user’s taskbar or dock. And they negate the advantages of a consistent, integrated interface.
We’ve got some tools that come closer to getting it right. Radio Userland‘s integration the two taks of aggregation and weblog authoring is terrific, even if its design of running a desktop web server is still dependent on a web browser-based user interaction model. Newzcrawler is closer in UI, but still damned clunky. It is mostly significant for being the client that includes the greatest number of pieces of the microcontent client today, at least until the release of NetNewsWire Pro, by including news aggregation, browsing, and weblog publishing in one application.
The greatest task that remains is integration. Nearly every piece exists today. Both Windows and Mac OS are finally in versions that are stable, with usable GUIs and solid networking code. Both expose OS-level HTML rendering, and have dozens of applications that can serve as models for parts of the microcontent client. Between the services that the operating system provides, and the formidable libraries of code produced by projects like Mozilla, we’re close to the birth of the first significantly new platform on the Internet since the World Wide Web a decade ago. But right now hordes of developers are wasting their time making clones of existing software instead of building future killer apps that can make their chosen platforms indispensable. The opportunity is still there for the taking.

(https://web.archive.org/web/20030604021320/http://www.brownhen.com/2002_10_20_backhen.html)building the client with mozilla
Several independent projects have already started to contribute building blocks. MIT’s Haystack research project is using Semantic Web RDF technologies to perform the background analysis and processing to assign context to content as the user works with it. Mozilla developers are using related ideas to generate content-appropriate UI for information that’s being browsed. Apple’s Sherlock channels are based on standards that can be implemented in a platform-independent manner. In fact, older Sherlock plug-ins were standard enough that an open implementation was reverse engineered. The only significant weakness of available code for these projects is the local storage system that would be needed for recording the large amount of contextual data generated by use of the microcontent client, and the Open Source Application Foundation’s newest hire is focused on creating a "world class" storage system. The pieces are coming together.
All that remains is the task of building this tool, shipping it to users, finding out how it sucks, and then making the improvements needed to actually usher the Semantic Web into place. The end of this process is the microcontent client, and the benefit is all of the advantages we gain from having learned from the strengths and weaknesses of the web browsers as the first generation of mainstream internet applications.
What’s Next: Are You Gonna Do It?
So who’s going to do all this work and development? And why are they going to do it? Well, probably, it’ll start with small commercial developers and open-source developers. The geeks will probably blow it at first by butchering the user experience as they’ve almost always done. But there are ample commercial opportunities for such a tool, and it could be a decided advantage to any platform vendor that decided to integrate it into their offerings.
(http://xulplanet.com/cgi-bin/ndeakin/homeN.cgi?ai=32)content-sensitive UI
There’s also a host of potential business models. The microcontent client could bootstrap micropayments by being purchased on a subscription basis that included several web services as part of its basic toolset. Vendors could tap into the client’s payment database to offer additional services for incremental fees. A percentage of the annual cost for the client could be allotted to an escrow fund, doling out payments to sites that offered properly-authored microcontent. Since users would have rating systems integrated right into their browsing tool, it would be trivial to track which sites had the strongest responses and would get the largest share of the fee.
We’ve already got at least three major vendors with Instant Messaging clients who are looking for ways to get users to pay a subscription fee for the service they’re dependent on. The microcontent client’s integration of instant messaging could leverage this database for identity information, while justifying a subscription payment as the compensation for the downloadable updates that let the client read, access, or search new types of information. Even the most spam-laden, inefficient email systems are able to lock in users merely by the inertial strength of a user’s email address. This loyalty would be infinitely stronger for a system that managed all of a user’s day-to-day information.
The most important information in any of our lives is the information we create
The combination of a financial incentive for content providers to have a well-crafted site with platform vendors being motivated to build the audience for the client could provide more than enough financial incentive to make the minor changes in the authoring processes and content-creation tools that would be necessary to fully exploit the features of the client. A marketing campaign presenting the microcontent client as analogous to iMovie, but with its medium being digital text instead of digital video, could get Wired back to making grand pronouncements about interactive storytelling again.
The biggest opportunities for this application, of course, aren’t ones that can be anticipated. That the microcontent browser is easily small enough to run on a handheld or mobile platform is no accident; microcontent belongs wherever people are. The biggest business obstacle to the adoption of this vision is that all of the marketing for .NET or web services or AOL Everywhere keeps trying to pretend that the user experience of current software is adequate for managing the information that people need. More importantly, it ignores the fact that the most important information in any of our lives is the information we create. So it’s time for someone to make a tool that works with information the way that people do, using the capabilities of the Internet that, after a decade on the web, we’ve only just realized we have.
It’s time for the microcontent client.